Обучение искусственных нейронных сетей
Привлекательной чертой нейровычислений является единый принцип обучения нейросетей - минимизация эмпирической ошибки. Функция ошибки, оценивающая данную конфигурацию сети, задается извне - в зависимости от того, какую цель преследует обучение. Но далее сеть начинает постепенно модифицировать свою конфигурацию - состояние всех своих синаптических весов - таким образом, чтобы минимизировать эту ошибку. В итоге, в процессе обучения сеть все лучше справляется с возложенной на нее задачей. Не вдаваясь в математические тонкости, образно этот процесс можно представить себе как поиск минимума функции ошибки E(w), зависящей от набора всех синаптических весов сети w (см. рис.1.6).
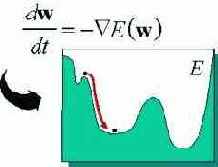
Рис. 1.6. Обучение сети как задача оптимизации
В основе большинства известных сегодня алгоритмов обучения нейросетей лежит метод градиентной оптимизации - итерационное изменение синаптических весов, постепенно понижающее ошибку обработки нейросетью обучающих примеров. Причем изменения весов происходят с учетом локального градиента функции ошибки. Эффективным методом нахождения этого градиента является так называемый алгоритм обратного распространения ошибки (error back-propagation). Разницы между желаемыми и фактическими ответами нейросети, определяемые на выходном слое нейронов, распространяются по сети навстречу потоку сигналов. В итоге каждый нейрон способен определить вклад каждого своего веса в суммарную ошибку сети простым умножением невязки этого нейрона на значение соответствующего входа. Простейшее правило обучения соответствует методу наискорейшего спуска - изменения синаптических весов пропорциональны их (весов) вкладу в общую ошибку.
Таким образом, одна и та же структура связей нейросети эффективно используется и для функционирования, и для обучения нейросети. Такая структура позволяет вычислять градиент целевой функции почти так же быстро, как и саму функцию. Причем вычисления в обоих случаях распределенные - каждый нейрон производит вычисления по мере поступления к нему сигналов от входов или от выходов.
Итак, базовой идеей большинства алгоритмов обучения является учет локального градиента в пространстве конфигураций для выбора траектории быстрейшего спуска по функции ошибки. Функция ошибки, однако, может иметь множество локальных минимумов, представляющих субоптимальные решения (см. рис. 1.6). Поэтому градиентные методы обычно дополняются элементами стохастической оптимизации, чтобы предотвратить застревание конфигурации сети в таких локальных минимумах. Идеальный метод обучения должен найти глобальный оптимум конфигурации сети.
